LinuxC 基础篇
Linux C
- Linux系统是基于C语言的一种类UNIX系统,其发布遵循GPL协议。
- Linux内核是系统的核心程序文件,其主要包括:中断服务程序、调度程序、内存管理程序、网络和进程间通讯等程序构成。
- Linux保留了UNIX的大多数特点:支持动态加载内核模块、支持对称多处理机制、不区分线程和其他一般进程。
- 本文章主要讲解如何在Linux环境下进行C语言程序设计。
1. C语言基础
下面介绍的C语言基础,是在有一定的基础上进行补充说明。
1.1 数据类型
- C语言的数据类型可以分为基本类型、构造类型、指针类型和空类型。
1.1.1 整型、实型、字符型
| 基本类型 | 特点 |
|---|---|
| 整型 | - |
| 实型 | - |
| 字符类型 | - |
1.1.2 枚举类型
- 枚举类型:假设变量仅有几种可能的值,可将其定义为枚举类型。
- 跟结构体一样,使用关键字
enum声明一个枚举类型,再用该枚举类型声明定义变量,如:
enum IE{ |
- 经常使用enum IE也不太方便,可以使用typedef进行重声明。
|
- 对于枚举类型还可以应用于:
// 当一个寄存器内容不太好记,可以使用枚举变量给每一位“起别名”。 |
1.1.3 构造类型
- 构造类型可以分为:数组类型、结构体类型、共用体类型。
| 构造类型 | 特点 |
|---|---|
| 数组类型 | - |
| 结构体类型 | 结构体支持==位字段语法==,如int led : 1。 |
| 共用体类型 | 与结构体类型类似,使用union关键字开头。 |
所谓的共用体类型就是:几个不同变量共用同一段内存的结构类型,成员的起始地址相同,故共用体的内存长度为其中最长成员长度。
-
最后一次赋值有效;
-
不能引用共用体变量,而只能引用共用体变量中的成员;
-
不能对共用体变量名赋值,也不能企图引用变量名来得到一个值;
-
C99允许用共用体变量作为函数参数;
-
共用体类型可以出现在结构体类型定义中,也可以定义共用体数组。反之,结构体也可以出现在共用体类型定义中,数组也可以作为共用体的成员。
union Data{ |
1.1.4 指针类型
对于指针类型,
int data,*point; |
1.2 运算符
| 运算符 | 特点 |
|---|---|
| +、-、*、/、%、++、–、= | - |
| <、>、>=、<=、!= | - |
| &&、||、! | 与或非 |
| &、|、^、~、<<、>> | 按位:与、或、异或、取反、左移、右移 |
其中,有些值得注意的细节:
- 对整数中某些位进行位操作时,可使用位操作运算符,
//使用掩码取出8~15位,并将其右移得到值 |
a += 1相当于a = a + 1,但是这种复合运算,只进行一次运算。- 任何数与自己做异或,结果为0。
表达式1 ? 表达式2 : 表达式3,三目运算符。- sizeof运算符返回类型字节数,typedef类型声明符。
- 结构体取成员“.”、指向结构体的指针取成员->,这就涉及到了结构体和结构体指针的区别,结构体指针存储的是结构体的地址。
- 而**"."运算针对的是结构体变量,而箭头运算符是针对的内存而言的,即像结构体指针这种动态分配地址的**。
struct Person { |
1.3 预处理命令
|
2. 内存管理
根据内存分配方式的不同,可将其分为:动态内存和静态内存。
-
动态内存:程序猿自行按需分配。
-
静态内存:是由编译器分配的内存,其在编译时完成,不占用CPU资源,变量的释放和分配系统自行完成。
对于其区别:
- 静态内存的使用不占用CPU资源,而动态内存是在程序运行时完成的,因此占用CPU资源。
- 静态内存是在栈上分配的,而动态内存是在堆上完成的。
- 动态内存的使用需要指针和引用数据类型的支持,而静态内存不用。
- 静态内存:计划分配,动态内存:按需分配。
2.1 内存操作
2.1.1 栈和堆
在计算机科学中,"栈"和"堆"是两种常用的内存分配方式,它们有以下区别:
- 分配方式:
- 栈(Stack):栈是一种后进先出(LIFO)的数据结构,内存分配和释放是自动进行的,由编译器管理。当您在函数中声明一个局部变量时,它会被分配到栈上,并在函数结束时自动释放。因此,栈上的内存分配和释放是快速的。
- 堆(Heap):堆是一种动态分配内存的方式,程序员手动分配和释放堆上的内存。堆上的内存分配和释放比栈上的操作更复杂,需要程序员来负责管理,包括内存的分配、使用和释放。
- 内存管理:
- 栈:栈的大小通常固定,并由编译器提前确定。它通常用于存储函数的局部变量、函数调用和参数。栈上的内存分配和释放是自动的,编译器负责管理,因此不存在内存泄漏的风险。
- 堆:堆的大小不固定,并且可以动态增长或缩小。在堆上分配的内存由程序员手动分配和释放,因此需要注意避免内存泄漏和悬空指针。
- 访问速度:
- 栈:由于栈上的内存分配和释放是由编译器自动管理的,因此栈上的操作通常比较快速。栈上的数据访问速度相对较快。
- 堆:堆上的内存分配和释放通常比栈上的操作慢,因为它需要更多的操作来管理动态分配的内存。因此,堆上的数据访问速度相对较慢。
- 分配方式:
- 栈:栈上的内存分配是连续的,每个变量的大小都是固定的。栈的分配和释放遵循后进先出的原则,所以在栈上分配的内存是连续的且按照相反的顺序释放。
- 堆:堆上的内存分配是不连续的,大小不固定,由程序员在运行时手动控制。因此,堆上分配的内存可以是不连续的。
2.1.2 分配和释放内存
可以通过以下函数实现动态内存的分配和释放:
| 函数 | 原型 | 特点 | 返回值 |
|---|---|---|---|
| malloc() | void *malloc(uint size) | 分配有size个字节的内存块 | 分配成功,则返回开辟内存的指针,否则返回NULL,与**free()**配合使用。 |
| calloc() | void *calloc(uint n,uint size) | 分配n个大小为size字节的内存块 | 同上 |
| realloc() | void *raelloc(void *p, uint newsize) | 调整p指针所指向内存大小为newsize个字节 | 有趣的是,当p为NULL,与malloc()类似,当newsize为0,则等于free()。 |
| memset() | void *memset(void *s,char ch,unsigned n) | 设置字符串s中所有字节为ch,s数组大小为n | 其实就是替换指针数组s中的字符,n代表字符数组的大小。 |
-
分配成功将返回分配内存的指针,否则返回NULL。
-
需要使用**free()**函数释放内存空间。
-
特别的,如果在realloc()函数中newsize大小为0,则相当于**free()**函数,释放内存空间。
|
2.2 链表
假设使用动态内存分配的方式,实现保存多名学生的学号、年龄以及成绩,直到输入为0结束。
|
值得注意的是:scanf()函数,在格式字符串中存在非格式控制字符时,必须严格符合格式要求。
- 例如,
scanf("%d,%d",&a,&b)中,输入必须为1,2,否则将会导致读取异常。
3. Vim和Emacs
3.1 VIM
VIM作为Linux系统下自带的基本编辑器,具有彩色和高亮等特性。对于VIM的使用:
- 终端输入vim,进入编辑器中。
- 退出vim,需要长按ESC键,输入
:,再输入q,按下ENTER,即可退出。
同时VIM具有三种模式:命令模式、编辑模式、底行模式。
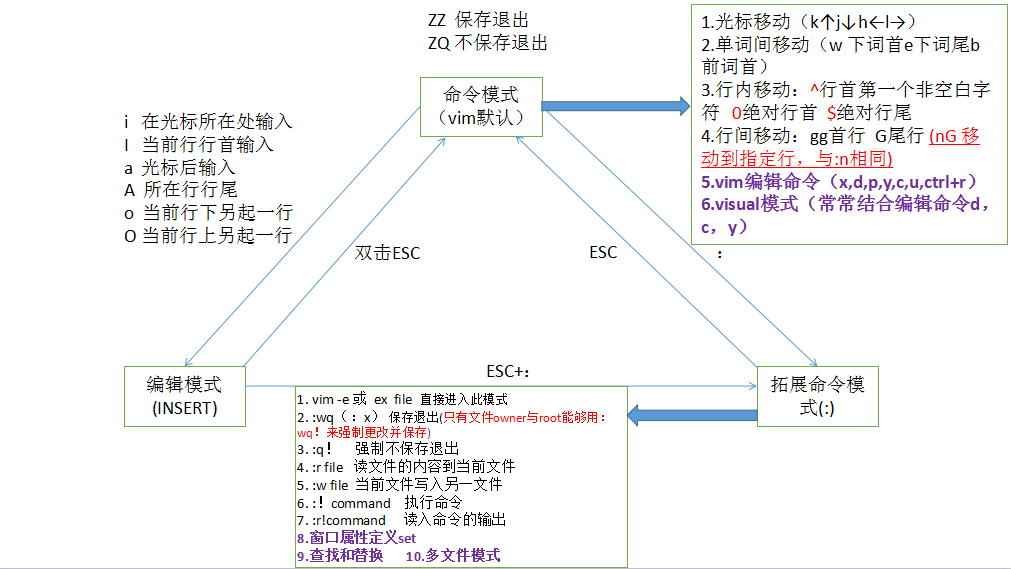
对于VIM命令行模式:
复制: |
删除: |
粘贴: |
常用: |
而对于VIM的底行模式:
| 命令 | 含义 |
|---|---|
| q wq x wq! | 退出 先保存再退出 强制保存并退出 |
| quit | 不保存退出 |
| w w filename | 保存为filename名的文件 |
| set nu set nonu | 显示行号 不显示行号 |
| /str ?str | 正、反向搜索str 按n继续查找 |
| recover | 恢复文件 |
| ce ri le | 本行内容居中、靠右、靠左 |
3.2 Emacs
4. GCC编译器
GCC是GNU C Compiler的缩写,由于技术的发展,现在已经可以编译C、C++、Ada、Object C、Java等语言了。故现在又称之为GNU Compiler Collection,具有交叉编译的功能,即可以在一个平台上编译另一个平台的代码。
4.1 GCC指令
gcc编译的基本用法:gcc [options] [filenames]
-o output_filename,确定输出文件名为outputfilename,这个名称不能和源文件同名。-c,只编译,不链接成为可执行文件,只生成由C文件生成的目标文件,通常用于不包含主程序的子程序文件。-g,产生符号调试工具(GDB)必要的符号资讯,通常用于调试。-O,对程序进行优化编译、链接,可提高执行效率。O2,比前者更好的优化,但编译过程变慢。-pedantic,能够帮助开发者找出不符合ANSI/ISO C标准的代码,但不是全部。-Wall,该指令能够使GCC产生尽可能多的警告信息。
-Werror,该指令将所有警告当作是错误处理,在使用make工具时,能够很好的在产生警告的地方停止。
建议在使用gcc指令时与Werror连用。
GCC编译程序时,可以细分为:预处理、编译、汇编、链接。
| 步骤 | 作用 |
|---|---|
| 预处理 | C预处理器CPP,主要用于解释宏定义、处理包含头文件。 |
| 编译 | 将源代码处理为.o格式的目标文件。 |
| 汇编 | 在使用gcc时,产生汇编代码,处理这些汇编代码就需要汇编器,从而使其成为目标文件。 |
| 链接 | 将项目的多个模块组合起来,结合相应的函数库,产生目标文件。 |
此外,除去GCC编译器外,还有一些其他的编译器:
g++,其使用的选项一样,但是是针对C++进行编译,保存其扩展名一般为:.cxx 。EGCS:gcc的未来模样,但是现在已经gg了。- F2C、P2C:代码转换器。
4.2 GDB调试
4.2.1 gdb预处理
GDB工具是通过bash命令行上实现的,要想使用GDB,必须在使用gcc编译时,附加上调试指令,使得生成文件包含调试信息。
调试符号:调试符号是将源代码与可执3行文件相联系的桥梁,可用作源代码级的条好似、栈回溯、按名称显示变量等。
gcc调试指令:
-g,可以在g后附加数字1、2、3来指定加入调试信息的多少,默认-g2。
| 代号 | 含义 |
|---|---|
| 1 | 不含局部变量和与行号相关的调试信息,只能用来回溯跟踪、堆栈转储。 |
| 2 | 包含拓展的符号表、行号、局部变量或外部变量信息。 |
| 3 | 在1、2的基础上,包含源代码中的定义的宏。 |
其中,回溯跟踪:监视程序在运行过程中的函数调用历史。堆栈转储:以十六进制保存程序执行环境的方法。
-ggdb,在生成的二进制代码中包含GDB专用的调试信息。
如果在使用gcc编译时,未附加调试指令,再使用gdb filename,则有:
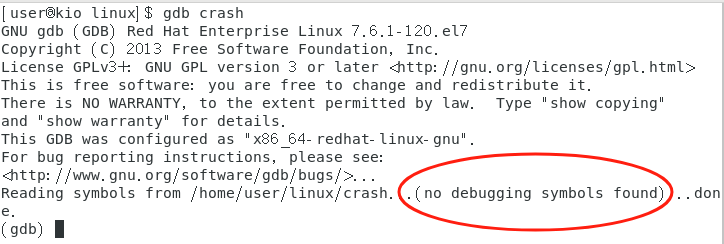
而在编译时,使用了调试指令,则再用gdb filename,此时已经显示读取到调试符号,再键入run指令,则有:
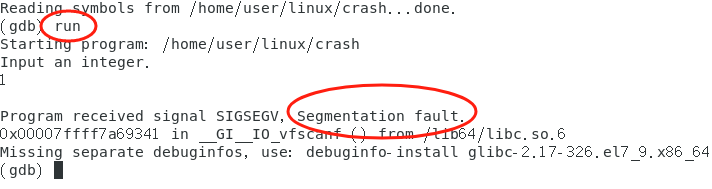
显然,此时程序错误为段错误(scanf("%d",input);),再使用回溯跟踪backtrace(查看函数调用历史)。
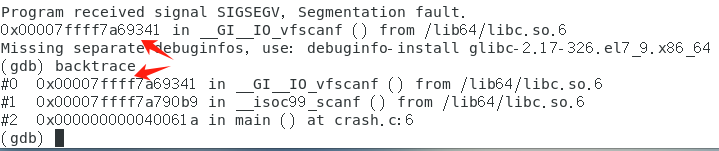
从#2错误可知,该问题出在crash.c文件中的第6句。
此外,使用GDB打开带有调试信息的文件时,还可以先进入gdb环境,再使用file 可执行文件名。
4.2.2 gdb调试
GDB还支持:单步跟踪程序、检查内存变量、设置断点等。在gdb环境中:
单步跟踪:
break n,在第n行设置断点。break 函数名,进入指定函数时停止。break ... if 条件,符合条件且运行到指定位置停止。enable,可以恢复暂时不起作用的断点,还可以恢复多个断点,使用空格断开。disable,设置断点失效,例如,程序在断点处停下,可以使用disable失效下一断点,再用continue继续执行。delete,clear,删除断点。clear清除断点需要标明行号,delete则需要标明编号。next,单步执行程序语句。step,进入子函数,step可以使用快捷键s代替,单步执行每一条语句。step与next的区别在于next将子函数视为一步。continue,继续执行程序。quit,退出。
检查内存变量:
-
print 变量/表达式,可以使用该指令输出变量/表达式值。 -
print $,表示给定序号的前一个序号,$表示这是第几次使用print指令。还有print $$。 -
print vari=value,print指令还可以给变量赋值。 -
print 开始表达式@连续空间大小,用于打印连续空间的内容,例如,print array[3]@2,打印从数组4开始的两个内容。 -
display,与print不同的是,每当运行到断点处时,都会显示表达式的值,适合在循环中观察变量的值。 -
disable display 序号, enable display 序号, delete display 序号,undisplay 序号,使能/失能、取消、取消显示。 -
whatis,ptype,whatis只显示数据类型,而ptype还可以给出类型的定义。 -
set,可用于修改大循环变量为需要的值,例如,set variable i=4。 -
x/<n/f/u> <addr>,查看内存,n、f、u为查看命令的可选参数,addr为起始地址。
| 代号 | 含义 |
|---|---|
| n | 表示显示内容的个数,即起始地址后几个的内容。 |
| f | 表示输出格式,默认情况下,取决于数据类型,但可选有: x d u o t c f:十六进制、有符号十进制、无符号十进制、八进制、二进制、字符、浮点 |
| u | 表示从当前地址向后请求的字节数,默认四字节,当指定字节长度后,GDB从指定内存地址开始读,可选: b h w g:字节、双字节、四字节、八字节 |
可以理解为:从addr地址开始以f格式显示n个u数值。
观察窗口:
watch 条件,被写变量/表达式设置监视点,一旦该值有变化,就立即停止程序。例如,watch i>3。rewatch,被读变量/表达式设置监视点,一旦该值被读取,就立即停止程序。awatch,当变量被读被写时,程序停止。info watchpoints,用于列出当前所设置的所有监视点的相关信息。
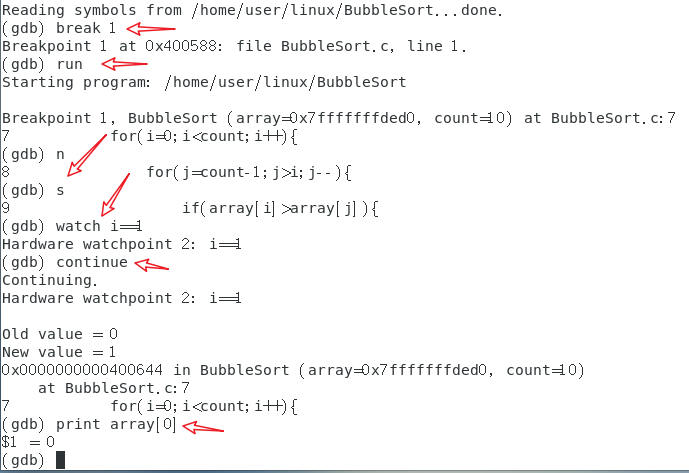
演示了:在第一行设置断点,使用next、step单步执行、观察窗口、查看变量值。
检查栈信息:
栈是一种有限定性的线性表,当程序调用函数时,函数的地址、函数参数、函数内的局部变量都被压入栈中。
通过GDB可以查看栈层消息:栈的层编号、当前函数名、函数参数值、函数所在文件及行号、函数执行到的语句。
backtrace,简写形式为bt,用于显示当前函数调用栈的所有信息。backtrace n,简写形式为bt n,n为正整数,显示栈顶上n层的栈信息,n为负数,则是显示栈底下n层的信息。frame n,简写形式为f n,n从0开始的整数,表示栈中的层编号,显示第n层栈的信息,没有n则显示当前栈层的信息。up n,向栈底方向移动n层,没有n,则表示移动一层,在栈中栈底位于高地址区域,因此用up,对应的有down。

info frame,简写形式info f,实现更为详细的栈层信息,例如:被调用函数地址、所使用的编程语言、函数参数地址及值、局部变量地址等。info args,显示当前函数的参数名及值。info locals,显示当前函数局部变量及其值。info catch,显示当前函数中的异常处理信息。
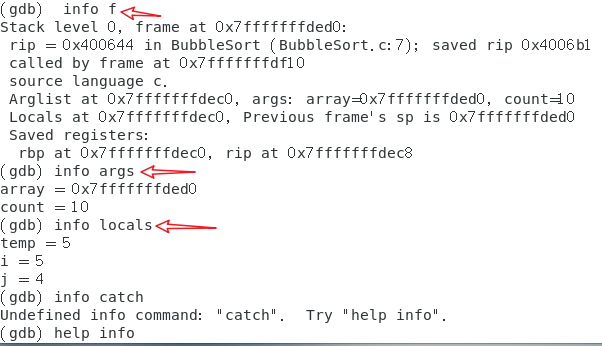
检查源代码功能及其命令:
在使用GDB工具时,通常加上-g参数,将源程序的信息编译到执行文件中,此外查看源代码的有:
list,不加任何参数表示显示当前行后面的代码。
| 参数 | 含义 |
|---|---|
| + | 显示当前行号后面的代码。 |
| - | 显示当前行号前面的代码。 |
| n | 显示程序第n行后的代码。 |
| function | 显示函数名为function的函数代码。 |
| first,last | 显示从first到last之间的代码。 |
| ,last | 显示当前行到last行的代码。 |
| filename:n | 显示文件名为filename文件中的第n行代码。 |
| filename:function | 显示filename文件中function函数的代码。 |
默认情况下,list命令会一次显示10行,可通过:
set listsize n,n为显示的行数,该指令可设置每次显示的代码行数。show listsize,显示当前行数显示设置。
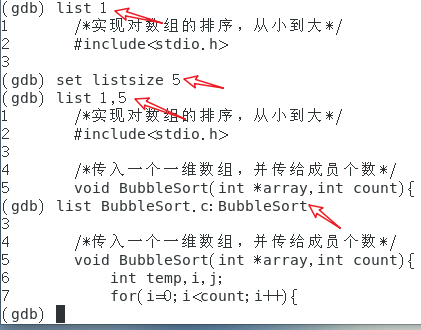
使用GDB调试程序时,难免需要查看某一行代码所在的内存地址等信息,故:
info line,用于查看程序在运行时所指定的源代码的内存地址,后跟行号或函数名。disassemble,反汇编,查看当前执行的机器码。
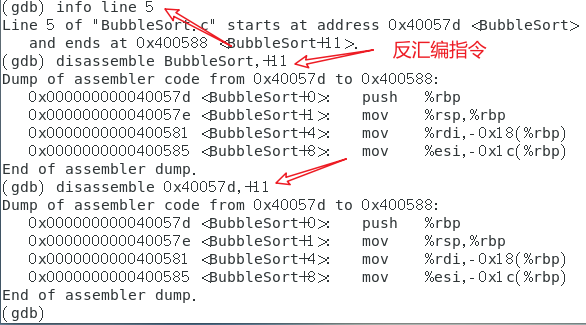
改变程序的运行功能及其命令:
调试程序时,并不是每条语句都需要执行,可以通过跳转语句,修改变量值的方式。
set var 赋值等式,改变变量的值,需要注意的是:若存在变量width,则避免set width,理应使用:set var width=5。set $ps=addr,更改跳转执行的地址。jump file:n,跳转到文件file的第n行。又或者是:set addr,跳转到地址为addr的语句开始执行。使用jump会忽略正常顺序。return,跳出函数,或返回一个值。call 表达式,用于显示表达式的值,如果表达式是函数名,则强制性跳转到该函数,并返回函数值,print也可同样使用。
多线程程序调试:
多线程已经被许多操作系统所支持,在LInux平台上的程序设计包括:多任务程序设计、并发程序设计、网络程序设计和数据共享等。
在Linux平台上,多线程遵循POSIX线程接口,称为pthread。
保存编译器中间结果:
gcc -save-temps foo.c -o foo,该指令是将编译器生成的中间结果保存,便于手工调整代码。-P和-pg,该指令会将刨析信息加入到生成的二进制文件中,便于开发者开发更加高性能的程序。
| 指令 | 含义 |
|---|---|
| -p | 在生成的代码中加入通用刨析工具能够识别的统计信息。 |
| -pg | 生成只有GNU才能识别的统计信息。 |
此外,虽然GCC允许优化与加入调试符号信息同时进行,但应当避免避免这种情况的出现。
4.3 代码优化
GCC提供的代码优化功能比较强大:
-
-On,来控制优化代码的生成,其中n代表优化级别,典型值:0 2 3。代号 含义 1 减少代码的长度和执行时间,一般包含线程跳转和延迟退栈。 2 在1的基础上,完成如处理器指令调度等。 3 在前者的基础上,完成循环展开等。
int main(void)
{
double counter;
double result;
double temp;
for(counter=0;counter<2000.0*2000.0*2000.0/20.0+2022;counter+=(5-1)/4)
{
temp=counter/1979;
result=counter;
}
printf("Result is %lf\n",result);
return 0;
}则通过系统
time指令查询运行时间,有: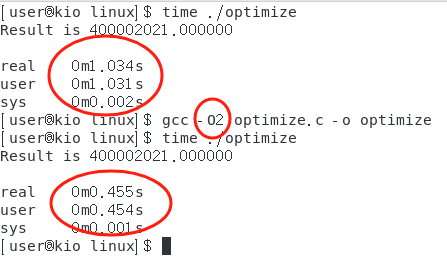
但是也要注意优化带来的一些弊端:
- 优化等级越高,编译时间越长。
- 优化会增加可执行文件的体积,特别是能够申请到的内存有限时,例如嵌入式设备中。
- 跟踪调试时,优化代码,会导致跟踪和调试变难。