LinuxC 提高篇
LinuxC 提高篇
上面我们已经初步介绍了,C语言的一些基本语法和拓展应用,
- 例如:枚举类型、结构体位字段、共用体以及内存的分配和释放,
- 其次再对Linux环境下的gcc编译器、VIM、GDB等有一个初步的介绍,
- 下面将进行一些核心技术的介绍。
5. linux进程控制
- 使用ps -aux查看系统中正在进行的进程信息。
我们理应知道:在Linux环境的进程特性。
- 动态性:进程是程序的执行,是程序在处理机上执行时的一个活动。
- 并发性:多个程序可以同时运行在同一内存空间上。
- 独立性:每个进程都是运行在各自的虚拟空间中,互不干扰,是独立获得资源和调度的基本单位。
- 异步性:各个进程都是按照自己运行速度执行。
- 结构特性:每个进程都具有自己的私有空间,在该空间中,进程由代码段、数据段以及堆栈段构成。
此外,进程也有属性信息。
- ID、状态、进程切换、虚拟内存、文件描述符、用户ID、组ID等。
5.1 创建进程
5.1.1 fork() 详解
在Linux系统下,进程的创建有函数:fork()、vfork()、exec()函数。
-
pid_t:用于定义进程的ID,可以理解为非负的整数。
-
fork():创建一个新的进程,新进程为当前进程的子进程,当前进程就被称为父进程,可以通过fork()函数的返回值,判断是在子进程还是父进程。
pid_t fork(void); |
若返回值为PID,即非负值,则代表运行在父进程中,pid为子进程号;若返回值为0,则表示运行在子进程中;若返回值为-1,则创建进程失败。
错误信息有:
- EAGAIN:表示fork()函数没有足够的内存用于复制父进程的分页表和进程结构数据。
- ENOMEM:表示fork()函数分配必要的内核数据结构时,内存不够。
// 演示一段程序, fork.c 文件 |
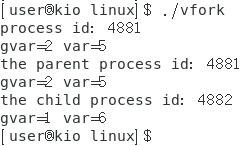
- 系统运行如下:

我们可以发现,fork()函数具有调用一次,返回两次的特性,这是一个值得深究的问题:
fork()函数创建新进程,这个新的进程是原进程的副本,包括它的代码、数据、堆栈等。fork()调用后,子进程会从调用fork()的地方开始执行,子进程会继承父进程的代码段,但是不会再次执行fork()调用之前的代码。
下面看一段演示代码:
|
- 经过我的验证,结果如下,并不会执行fork()前的代码:

5.1.2 vfork() 详解
**vfork()函数与fork()**函数相同,但,
-
fork()函数会复制父进程的所有资源,包括:进程环境、内存资源等,而vfork()函数在创建子进程时,不会复制父进程的所有资源,父子进程共享地址空间。所以在子进程中修改内存空间中的变量时,实际是在修改父进程虚拟空间中的值。
-
值得注意的是,在使用vfork()函数时,父进程会被阻塞,需要在子进程中调用_exit()函数退出子进程,不能使用exit()函数退出。
|
如上图,其结果为:
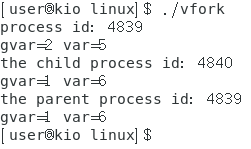
可以看出,在子进程中操作变量,也是改变父进程的中的值。可以将vfork函数换为fork函数。通过对比可知,符合结论。
5.3 编辑进程
我们经过上面的学习后,知道如何建立一个进程,但复制父进程代码是没用的,我们希望子进程进行不同的操作,故:
- exec()函数族:Linux系统提供了一个exec()函数族,用于修改进程(执行新程序)。
- 调用exec()函数时,子进程中的代码段、数据段和堆栈段都将被替换,由于exec()函数并没有创建新进程,故子进程ID不变。
- exec函数族的函数执行成功后不会返回,调用失败时返回-1,然后从原程序的调用点接着往下执行。
- exec()函数有,
int execl(const char *path,const char *arg,...); |
- 参数解释见后,
这些函数都定义在**<sys/types.h>、<unistd.h>两个库中,且必须在预定义时定义一个外部的全局变量**:
extern char **environ; |
- 上述定义的变量是一个指向Linux系统全局变量的指针,定义后,就可以在当前工作目录中执行系统程序,如同在shell中不输入路径直接运行VIM和等程序一样。
| 函数 | 作用 |
|---|---|
| execlp 带p | path,直接使用文件名,会自动在PATH中寻找。 |
| execl 带l | list,代表使用参数列表,参数个数不定,结尾以NULL结束。 |
| execv 带v | vector,代表需要先构建参数数组指针,并将该地址作为输入,数组中最后一个指针也要输入NULL。 |
| execv 带e | environment,代表使用新的环境变量表代替调用进程的环境变量表。 |
5.3.1 execve()
-
execve()函数的作用是创建一个子进程,在子进程中执行另一个执行文件。
-
int execve(const char *path,const char*argv[],char *const envp[]):其参数解析,
| 参数 | 含义 |
|---|---|
| const char *path | 指向字符型的常量指针,为文件的路径。 |
| const char*argv[] | 参数数组,每个指针指向一个以 null 结尾的字符串,第一个参数为程序名称,后面为命令行参数。 |
| char *const envp[] | 环境变量数组,每个字符串都表示一个环境变量。 |
其中execve()函数是其余5个exec函数的基础,只有execve()函数才经过系统调用,故使用其它函数后,都需要最后调用execve()函数。
/*execve.c文件*/ |
对主函数的参数我有点想说的:
这是 C 语言中定义主函数的典型方式之一。让我们一一解释每个参数的含义:
int argc:这是表示命令行参数数量的整数。argc是 “argument count” 的缩写,它表示在运行程序时通过命令行传递给程序的参数数量,包括程序的名称在内。char *argv[]:这是一个指向字符(char)指针的数组。argv是 “argument vector” 的缩写。它包含了指向以 null 结尾的字符串的指针,每个指针指向一个命令行参数的字符串。argv[0]通常是程序的名称,而后续的元素则是传递给程序的命令行参数。- 在生成可执行文件时,操作系统不会直接提供主函数的参数。相反,当你在命令行中执行该可执行文件时,操作系统会为你传递参数。在命令行中执行程序时,你可以通过在命令后面添加参数来传递给程序,如:
./my_program arg1 arg2 arg3 |
结果:
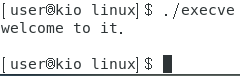
-
显然输出为
welcome to it.,但是没有输出“正常无法…”,这是因为使用execve函数,已经把代码段、数据段、堆栈段进行替换了,原来的代码就被抛弃了。 -
如果不想因为调用这个函数就抛弃了其余代码,则可以将其余部分放置在父进程中。
如:
/*修改execve文件*/ |
5.3.2 execlp()
下面演示**execlp()**函数:
|
运行结果如下:

- 其余exec()函数都大同小异,只是参数不同。
5.4 进程等待
刚刚我们发现,由于子进程和父进程是两个独立的进程,会存在父子进程传递消息以及消息等待的需求,这就需要进程等待。
-
通常需要调用wait()等待函数使父进程等待子进程结束,否则子进程会进入**僵尸(Zombie)**状态。
-
使用
man 2 wait指令查看wait()函数原型:
|
wait() 函数的工作方式如下:
- 如果当前进程没有子进程,
wait()函数会立即返回 -1,表示没有子进程可以等待。 - 如果当前进程有一个或多个子进程正在运行,则
wait()函数会挂起当前进程的执行,直到一个子进程结束。 - 当某个子进程结束时,
wait()函数会返回结束的子进程的PID,并将其退出状态存储在status指向的位置。然后,该子进程的进程控制块会被清除,它占用的资源会被释放。 status:为指向整数的指针,存储子进程的退出状态信息,如果不关心子进程的退出状态,可以将status参数设置为NULL。wait()函数只能等待一个子进程结束,如果希望等待所有子进程结束,可使用变体函数waitpid()或者waitid()。
若存在子进程,退出进程时的结束状态可分为:
- 子进程正常结束:函数返回子进程的PID和状态,此时的参数status指向的状态变量就存放在子进程的退出码中,退出码是所谓的从子进程的main()函数中返回的值或子进程中exit()函数的参数。
- 信号引起子进程结束:wait()函数系统发送信号给子进程,可能导致子进程结束运行,若发送的信号被子进程捕获,则终止子进程,此时参数status返回的状态值为接受到的信号值,存放在最后一个字节中。
|
- 在Linux系统中可以使用 kill _l 查看这些信号的具体情况、信号类型以及对应数字。
- 上述代码用到了一些状态宏:
| 宏 | 含义 |
|---|---|
| WIFEXITED(status) | 子进程正常结束,返回值为1,正常退出是用exit、_exit。 |
| WIFSIGNALED(status) | 子进程没有被捕获的信号终止时,返回为1。 |
| WIFSTOPPED(status) | 子进程接收到停止信号,返回1,这种情况只出现在waitpid()函数使用了WUNTRACED选项。 |
| WEXITSTUTAS(status) | 当WIFEXITED(status)为真时调用,返回状态码的低8位。 |
| WIFCONTINUED(status) | 接受信号后,继续运行。 |
| WTERMSIG(status) | 当WIFSOGNALED(status)为真时调用,返回引起终止的信号代码。 |
| WSTOPSIG | 当WIFSTOPPED为真时,返回进程停止的信号类型。 |
- 除了wait()外还有waitpid(),其区别是:wait用于等待所有子进程结束,而waitpid用于特定pid进程。而waitpid中pid参数与实际控制的pid参数,有:
| 关系 | 含义 |
|---|---|
| pid<-1 | 等待进程组ID与pid绝对值的任一子进程相等时退出。 |
| pid=-1 | 等待任意一个子进程退出。 |
| pid=0 | 等待进程组ID与调用进程的组ID的任一子进程相等时退出。 |
| pid>0 | 等待进程ID等于pid的子进程时退出。 |
| WNOHANG | 表示没有子进程退出就立即返回。 |
| WUNTRACED | 表示发现若子进程处于僵尸状态但未报告,则立即返回。 |
5.5 进程结束
想终止和结束一个进程时,使用以下函数:
- exit():
|
- _exit():对于fork()创建的子进程,只能使用此函数关闭。
|
其区别:
- exit()会在终止进程时关闭所有文件,清空缓冲区,会对输入/输出流刷新,可能会导致文件的丢失。
- 尽量减少使用exit()终止子进程。
5.6 多个进程间的关系
随着硬件的发展,很多系统都拥有多个处理器,Linux系统是一个支持多进程同时运行的系统,但是想要多个进程合理运行,需要注意。
5.6.1 进程组
进程组:就是一个或多个进程的集合。
- 在Linux系统中可以通过调用getpgrg()函数获取进程组ID,原型为:
|
- 进程的生命周期:从创建进程到进程终止,进程组的生命周期:进程组的创立到进程组中最后一个进程终止。
- 在Linux系统中,可以说使用setpgid()函数创建一个新的进程组或将一个进程加入到一个进程组中,其原型:
|
下面演示获取进程ID和获取进程组ID,以及创建一个新的进程组:
|
5.6.1 时间片的分配
我们学过单片机,知道很多单片机都是单线进行,那么对于一个CPU来说可以实现多进程同时运行吗?
实则只是将多个进程进行时间切片,近似看做同时进行,那么,
- 时间片:每个进程都有其时间段,这个时间段称为进程的时间片。
要想多个进程的时间片合理运行,则需要进行任务调度,时间片切换的调度策略有:
- 时间片轮转调度策略:遵循先来先得的原则运行,按顺序执行时间片。
- 优先权调度策略:有些进程需要优先处理,则引入优先权调度算法,其分为两种,
- 非抢占式优先权调度策略:将CPU分配给队列中优先权最高的进程,然后全速执行该进程。
- 抢占式优先权调度策略:将CPU分配给当前优先级别最高的进程,每出现新的进程就进行比较。
在Linux系统中提供以下函数用于设置和获取进程的调度策略等信息:
|
- setpriority()、getpriority():用于设置和获取进程的动态优先级。
- nice():用于改变进程的动态优先级。
5.7 线程
我们学习了进程,那么对于线程是什么呢?有:
- 定义:
- 进程:进程是计算机中运行中的程序的实例。它是程序的执行过程,包括程序、数据和进程控制块等资源的集合。
- 线程:线程是进程内的一个执行单元,也称为轻量级进程。一个进程可以包含多个线程,这些线程共享进程的资源。
- 资源占用:
- 进程:每个进程都拥有独立的内存空间、文件描述符、堆栈等资源。进程之间的通信需要使用特定的机制,比如管道、消息队列等。
- 线程:线程是在进程内部运行的,它们共享相同的内存空间和其他资源,比如文件描述符、堆栈等。因此,线程之间的通信更为简单,可以直接访问共享的内存。
- 切换开销:
- 进程:由于每个进程拥有独立的内存空间,进程切换的开销相对较大,涉及到切换页表、刷新 CPU 寄存器等操作,因此效率较低。
- 线程:线程切换的开销比进程小得多,因为它们共享相同的地址空间和其他资源,只需要切换线程的上下文即可。
- 并发性和并行性:
- 进程:由于进程之间拥有独立的内存空间,因此进程之间的并发性较高,但是实现并行需要多个处理器。
- 线程:线程可以在同一进程内并发执行,共享相同的资源,因此线程的并发性比进程更高。在多核处理器上,线程可以实现真正的并行执行。
- 稳定性:
- 进程:一个进程的崩溃通常不会影响其他进程,因为它们拥有独立的地址空间。
- 线程:一个线程的崩溃可能会导致整个进程的崩溃,因为它们共享相同的资源。
- 总之:进程适合于执行独立任务或者需要较高隔离性的情况,而线程适合于需要共享资源并且需要更高并发性的情况。
5.7.1 线程属性
同样的,我们要使用线程,就必须知道其属性,基于Linux系统,学习相关属性函数对线程进行操作。
- 例如线程属性结构体:
typedef struct{ |
- 值得一提的是:有人疑惑int后面怎么有双下划线,这是编程规范,防止与用户标识符冲突,一般在编译器和库时使用。
下面解释以下参数:
detachstate:取PTHREAD_CREATE_JOINABLE:表示可连接状态;取PTHREAD_CREATE_DETACHED,表示分离状态。schedpolicy:该变量表示线程的调度策略,取SCHED_OTHER:表示为普通、非实时的调度策略;取SCHED_RR:表示实时、轮转的调度策略;取SCHED_FIFO:表示实时、先进先出的调度策略。schedparam:表示线程的调度参数,该值由线程的调度策略决定。inheritsched:表示线程的继承性,取PTHEAD_EXPLTICIT_SCHED,表示从父进程处继承调度属性;取PTHEAD_INHERIT_SCHED,表示从父进程继承。scope:表示线程的作用域,取PTHREAD_SCOPE_SYSTEM时,表明每个线程占用一个系统时间片。
5.7.2 初始化属性对象
当需要使用一个线程的属性对象前,需要首先初始化该对象,初始化线程属性的函数为:
|
- 调用成功返回0,失败为非0值,
- 该函数必须在创建线程函数前调用,可以使用参数attr初始化线程属性对象。
|
- 该函数作用就是摧毁**attr指向的线程属性对象。
5.7.3 设置线程状态
线程的分离状态决定了线程是如何结束的,默认状态是可连接状态,这样线程在进程没有退出之前不会释放线程所占用的资源,可以调用pthread_join()函数来等待其它线程的结束,这样线程结束后会自动释放掉自身所占资源。
|
attr:用于设置线程属性的参数,指向要设置的线程属性对象;作为获取线程属性的参数,attr为获取的属性信息。detachstate:同理。
5.7.4 设置调度策略
上文中介绍到的三种调度策略:SCHED_OTHER、SCHED_RR、SCHED_FIFO。
然后使用以下函数进行设置和修改,
|
- 其它属性见函数说明。
关于进程的一些碎碎念:
- 我初学者,感觉这部分有点空,讲的也很浅,等我后面学厉害了进行补充,
- 还有就是关于进程ID的获取、用户UID的获取、组ID和有效组ID,前面有讲解,也可以使用man命令查看。
- 可以进入
/etc/passwd里查看,如图,

5.7.5 设置进程标识
对于用户ID的设置:
|
setuid(uid_t uid):如果传递时普通用户的用户标识,会成功将参数UID赋给进程UID;而使用管理员的UID作为参数,该函数会检查调用的有效用户ID,如果确定为管理员UID,则所有与用户进程有关的ID都会被设置为参数uid值。setgid(gid_t uid):如果调用该函数的用户为系统管理员,那么真实用户组ID和已保存用户组ID也会同时设置,该函数修改发出调用进程的ID时,不会检查用户身份。
代码演示为,
|
结果,

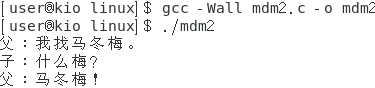
好了,我也不懂,那就做两个练习吧:
- 练习1:创建一个新进程,在父进程中输出“我找马东梅。”,在子进程中输出“什么梅?”,父进程等待子进程结束,输出”马冬梅!“。
|
结果:
- 练习2:使用
execl()代替一个hello.c文件,在hello.c中实现"Hello world!"。
/*execl_test.c文件*/ |
结果:

6. 进程间通讯
进程间通讯:Inter-Process Communication(IPC),多个进程间传递或交换信息。
- 进程与进程相互独立,互相传递信息,则需要在内核中开辟一块缓冲区域,在内核实现进程间的通讯。
- 进程通讯包括:管道通讯、共享内存通讯、信号量通讯、消息队列通讯、套接口通讯(SOCKET)和全双工管道通信。
- 除了支持信号和管道外,还支持SYSV(System V)子系统中的进程间通讯机制,在该机制下,包括:共享内存、信号量、消息队列通信。
6.1 管道
管道:主要用于父子或兄弟进程间的数据读写。
6.1.1 管道定义
- 管道的定义:数据只能朝一个方向传播,不能同时出现两个方向,这跟单片机通讯中的半双工模式类似,一边读,一边写,但是有些UNIX系统中,管道支持全双工通讯。
- 管道的创建和关闭:
|
- pipe()函数:在内核创建一个管道,一端读,一端写,创建完成后会获得一对文件描述符,用于读写和写入,然后将获取到的filedes[0]传给读端,filedes[1]传给写端。
- 错误信息:EFAULT(参数filedes非法)、EMFILE(进程使用了过多文件描述符)、ENFILE(打开的文件超过系统最大值)。
- 对管道的读写:read()、write(),关闭使用close()。
6.1.2 管道通讯
pipe函数只允许有联系的进程进行通讯。
管道通讯原理:
- 在父进程调用pipe()函数,父进程生成filedes[0]读和filedes[1]写。
- 在父进程中调用fork()函数,子程序复制所有,也包括filedes[0]读和filedes[1]写。
- 关闭父进程的filedes[1]和子进程的filedes[0],即留下父进程读和子进程的写。
- 即实现了pipe通讯。
下面进行演示:
|
根据我的实验:
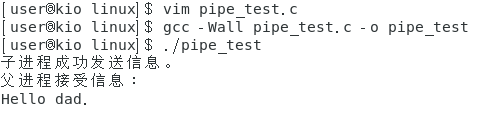
- write()函数:发送数据后,并不会显示在终端,需要自己打印。
- 有一个巨坑!!!,上述代码输出:

没错,是不是怪怪的,打印顺序错了…,聪明的你能想到为什么吗?
- 这是因为
printf()函数和write()函数的输出缓冲机制导致的。在标准输出中,printf()函数和write()函数的输出可能会被缓冲,直到缓冲区满或者遇到换行符\n时才会被刷新并输出到终端。由于子进程先于父进程结束,并且它的输出中包含了换行符,因此子进程的输出会立即被刷新并显示在终端上。 - 故:
printf("父进程接受信息:\n"); |
是的就是这个问题,最终输出:
双向通讯:使用两个管道。
6.2 命名管道
命名管道解决的是没有关系的进程间通讯。
- 命名通常又称之为FIFO,遵循先进先出的原则,作为特殊的设备文件存在于文件系统中,在进程中可以使用open()和close()函数打开和关闭管道。
- 区别:命名管道提供一个路径名,以特殊的设备文件形式存放在文件系统中,因此两个进程间可以通过访问该路径来建立联系,进行数据交换。
- 有两种创建命名管道的方法:通过函数创建,通过终端命令。
6.2.1 终端创建命名管道
在shell中输入mknod、mkfifo命令可以创建一个命令管道。
mknod [选项]... 路径名称 类型 // 参数p是指创建一个命名管道文件 |
mkfifo [选项] 名称 // 建议使用mkfifo -help |
可以看出mkfifo函数较为简单:
|
参数解析:
- pathname:文件路径名。
- mode:文件权限,权限值取决于(mode&~umask)。
- 访问管道文件跟其它文件一样。
- 进程阻塞状态:命名管道读取数据时,没有其它进程向命名管道文件中写入数据,会导致阻塞,同样的,只写入,不读取,也会。
- 读写操作前,要先使用open()函数打开文件。
代码演示:
|
以上代码的实现流程:
- mkfifo()创建一个命名管道,路径名称为:/home/cff/8/fifo4。
- open()函数打开该命名管道文件,以读写方式打开。
- 调用write()函数向文件写入信息”hello world“,同时用read()读取。
- 调用close()函数关闭文件。
- 使用open()函数打开文件后,记得读写同步,否则要出现进程阻塞!
6.3 共享内存
6.3.1 IPC对象
管道和命名管道都是基于文件系统的通讯方式,而SYSV子系统的进程间通讯是基于系统内核的。
共享内存、信号量和消息队列通常被称为IPC对象,每个对象都有唯一标识。
-
IPC标识符:唯一,通过传递IPC对象的标识符可以访问该对象。
-
IPC键:键是IPC对象的外部标识,由自己定义,多用于多个进程都访问一个特定的IPC对象,创建IPC对象时需指定键值,如果键值是公共的,则经过权限检查的都可以访问该IPC对象,如果该键私有,一般赋值为0,系统类型为系统定义的key_t类型。
-
IPC属性:查看<sys/ipc.h>,或者在shell中输入,
man ipc.h。
struct ipc_perm{ |
- IPC命令,
- ipcs:查看ipc对象信息,有共享内存、消息队列、信号量。带参数:q 消息队列;s 信号量;m 共享内存信息。
- ipcrm:用于删除指定的ipc信息,用法如下:
ipcrm -m shmid // 删除值为shmid的共享内存消息 |
6.3.2 共享内存相关操作
共享内存所实现的进程间通讯是最快速的,但当多个进程读取同一内存时,易数据混乱。
- 使用共享内存时注意进程间同步,即要用到信号量。
- 每个共享内存的对象都有其指定的定义类型,如:
struct shmid-ds{ |
下面进行相关函数讲解:
- shmget():详情见
man shmget。
|
- shmat():详情见
man shmat。
/*功能是将共享内存区域附加到指定进程的地址空间中*/ |
- shmdt():详情见
man shmdt,值得注意的是:shmaddr为shmat返回的地址指针,只是将其分离出来,共享区域仍然存在。
/*当某一进程不再使用该内存区域时,将shmdt指定的内存区域从该进程中分离出来。*/ |
- shmctl():详情见
man shmct,
/* |
| cmd | 含义 |
|---|---|
| IPC_STAT | 内核中,与标识符shmid相关的共享内存中的数据赋值到buf指向的共享区域中。 |
| IPC_SET | 根据参数buf指向的shmid_ds结构中值去设置shmid指向的共享内容的相关属性。 |
| IPC_RMID | 删除shmid标识符指向的共享内存区域,必须确保删除,否则该内存区域将不能释放。 |
| IPC_INFO | 该值为Linux特有,用于获取关于系统共享内存限制和buf指向参数的信息。 |
| SHM_INFO | Linux特有的,用于获取一个shm_info结构共享内存消耗的系统资源信息。 |
| SHM_STAT | Linux特有的,与IPC_STAT相同,但是shmid不代表标识符,代表内核中维持所有共享内存区域信息数组的索引值。 |
| SHM_UNLOCK | Linux特有的,用于解锁共享内存区域。 |
说了这么多,其实感觉就是废话,看代码吧:
|